
※ 본 포스팅에 등장하는 모든 가상(허구)의 인물이며 현실의 사건, 단체, 인물과는 관련이 없습니다.
※ 이미지는 이해를 돕기위한 참고용사진으로 등장인물과는 아무런 관련이 없습니다.

새로운 논문리뷰 재명은 합니다!
안녕하세요 Generative Adversal Nets의 리뷰를 맡은 리재명 이라고합니다.
AI 지금!
동훈이 합니다
안녕하세요 같이 논문리뷰를 맡게된 환동훈이라고 합니다.
오늘 우리가 함께 검토할 논문 Generative Adversal Nets는 정의와 상식의 나침반에 근거해 생성형 모델의 패러다임을 바꾸었다고 평가받는 논문입니다. 검찰 시절 쌓은 경험을 토대로 논의를 전개하겠습니다.
"결론 도출 과정에서 소홀한 부분이 있을 수 있으나, Easy Reading을 최우선 원칙으로 삼았음을 강조드립니다"
국민들의 눈높이를 외면한 기술논문 선정이라고 할 수 있겠습니다.
국민 여러분! 이 포스팅은 밤샘 작업하시는 근로자 분들의 눈 편안함을 최우선으로 설계했습니다. 꼭 다크모드로 설정 변경 부탁드립니다!
이 논문은 가짜와 진짜를 가르는 "공정한 경쟁 시스템"을 만들었습니다. 마치 시장에서 상인과 감정사가 서로 견제하듯, 두 AI가 서로를 열심히 검증하게 했습니다.
상인 G (데이터 분포를 통해 생성)와 감정사 D (테스트 데이터가 G, 샘플 어디서 왔는지 판별) 2가지의 모델이 학습을 진행하고요
대기업-중소기업 상생 모델처럼, 경쟁이 결국 시장을 발전시켜 상인(G)이 감정사(D)를 속이려 할수록 감정사는 똑똑해지고 상인은 점점 정교해지는 선순환 구조입니다!
또한 본 논문은 마르코프체인, 근사추론네트워크 등 90년대 구청 업무 방식 같은 구닥다리 방식을 청산함에도 다층 퍼셉트론 신경망을 사용가능하다고 하네요
과거 대장동 개발 당시 투명한 입찰 과정을 거쳐 최고의 결과물을 낸 것과 원리가 같습니다. 경쟁이 진정한 발전을 이끕니다.
듣기만 해도 피곤해지는 말들이군요 독자를 고려하지 않았다고 생각하지 않으시나요?
마르코프체인, 근사추론네트워크, 다층 퍼셉트론 과 같은 전문용어에 대한 설명을 해드리죠
우선 기존의 모델들은 직접 샘플을 생성하지 못했습니다. 분포 추정이 힘들고 계산이 너무 많이 필요했기 때문이지요.
근사추론네트워크란 샘플을 생성하는 대신 분포를 근사, 추론하여 계산을 줄인 샘플링 방식입니다.
마르코프체인이란 근사추론네트워크의 한 방식으로 확률분포가 반영된 데이터를 샘플링하는 것입니다.
GAN에서는 직접 샘플을 만들기 때문에 위와 같은 과정이 필요없습니다.
다층퍼셉트론이란 위와 같이 여러층으로 이루어진 퍼셉트론을 말합니다.
복잡하지만 아주 미세한 변화도 쉽게 감지할 수 있습니다.
국민들의 수준을 완전히 무시한 발언이라고 생각되네요
계속 그런식으로 말하시면 저는 뭐 진행을 하라는겁니까 말라는겁니까?

(하.... 또 저러네..)
제 생각도 제가 말하지 못하면 논문리뷰는 할 수 없는것 아닙니까?
일단 Introduction으로 진행하겠습니다.

지금까지 딥러닝에서의 큰 성공은 역전파 알고리즘, 드롭아웃 알고리즘에 기초한 선별 모델이었고 그에 반해 생성형 딥러닝은 영향력이 적었습니다. 그 이유로는 힘든 확률적 계산, 선형유닛의 이점 (판별기능)을 사용하기 힘듦 2가지가 있습니다. 그렇기에 이 논문은 새로운 생성형 모델, 즉 상인과 감정사의 관계처럼 서로 싸우는 모델을 제안합니다.

이 프레임워크는 구체적인 적대적 신경망이라 불리는 학습 알고리즘을 만들게됩니다. 생성, 판별모델이 다층 퍼셉트론인 알고리즘입니다.
또한 해당 모델들은 역전파, 드롭아웃 알고리즘 사용만으로도 성공적인 결과를 내놓았고 생성모델은 순전파만 진행하여도 좋은 결과를 냈다고 합니다.
다음 Related Work부턴 재명씨가 설명하시나요?

하하 그렇다면 관련된 연구는 저 재명이 설명해도 될까요?

저는 재명씨가 설명하라는 말씀을 드린적이 없습니다.

하하 사람 말을 참.. 제가 설명하겠습니다?

하시죠

알겠습니다. 관련된 연구에 대해서 알아볼까요?

RBM과 DBM은 계산이 어렵다는 치명적 약점! MCMC라는 돌아가는 방법으로 버티긴 했지만, 현실적 한계가 명확했습니다. 문제는 DBN입니다. 방향층과 비방향층을 혼합했다는 아이디어는 좋아 보였죠. 하지만 정작 계산은 양쪽의 단점만 모아놓은 꼴이 됐어요. 마치 자동차에 말발굽을 단 격입니다. 빨리 가려고 엔진 개선했는데, 오히려 마차 부품이 발목을 잡는 모순!

Score matching이나 NCE는 말이죠, 확률밀도라는 걸 전부 알아야 한다는 치명적 한계가 있습니다. 이건 마치 레시피 하나 만드는데 전 세계 요리법을 다 알아야 한다는 거랑 같은 거고 잠재변수가 많은 생성모델에서는 말이죠, 이런 확률밀도를 다 명시하는 게 불가능합니다. 불가능! 마치 복잡한 공사현장에서 모든 나사 하나하나 개수를 세는 것과 같은 비효율이죠!
NCE는 GAN처럼 판별학습을 쓰긴 합니다만, 문제가 있어요. 제대로 된 분포 하나 학습하면 속도가 영 느려집니다. 그래서 새 기술들은 확률분포 같은 복잡한 걸 아예 버리고 샘플 추출에만 집중합니다. 마치 선거 여론조사처럼 말이죠. 전수조사가 아닌 표본조사로 가는겁니다!
그래서 GAN은 피드백 루프가 필요하지 않기 때문에 일을 한번에 끝냅니다! 쌍팔년도 공무원식에서 벗어나서 이제는 구조 그 자체를 바꿔야한다는겁니다! 마치 도지사 시절 저처럼 말이죠!

좋은 비유였습니다. 재명씨
다만 본인 PR은 요청드린적이 없습니다만

GAN이 마치 저처럼 일을 잘하니까 저도 모르게 말이 나왔나보네요 허허
동훈씨도 적대적 신경망에 대한 설명 잘 하실수 있으시겠죠?

그럼 시작해보겠습니다.

여기서는 변수에대한 설명들이 들어가있습니다. 제가 메모장으로 정리해서 드리도록 하겠습니다.

간단하게 논문의 변수들을 메모장으로 옮겨봤습니다.

거 그렇게 딱딱하게 설명하면 독자들은 오래 머무르지 않을 수도 있다는걸 알고계시죠?

저희 독자분들은 저런 변수쯤이야 쉽게 알거라 생각합니다.
또한 모호한 화법을 구사하는 여의도 사투리를 쓰고싶지 않습니다.
이어 설명하겠습니다.

이에 관한 설명도 메모장으로 하겠습니다.


여기까지는 쉽게 이해가 되시리라 생각합니다.
그리고 상인이 처음 시작했을때는 감정사가 높은 확신을 가지고 판별하기 때문에 log(1-D(G(z))를 최소화하는 것 보다 D(G(z))를 최대화하는 방향으로 학습하면 효율이 좋습니다. 왜냐하면 log함수이기 때문입니다.
또한 G를 한번 최적할때 D를 여러번 최적화를 진행한다고 나와있습니다.

왜 최적화를 여러번 진행하는 이유를 설명하지 못하는겁니까?
번역만 할 생각이였으면 번역기를 사용하지 설명하지 못하면 이렇게 말할 이유가 없지 않습니까?

저는 설명을 못하지 않습니다.
또한 설명을 안한다고 하지도 않았는데요?
제가 설명을 안하고 넘어갈거라 생각한다는건 어떻게 아시죠?

저저 예의없는 xx가 확 그냥 ㅉ

어이쿠 빨리 설명하도록 하겠습니다.
D는 최적의 상태 근처에 있고 G가 천천히 변화해야 학습이 잘되기 때문입니다. 상인이 급격하게 품질을 바꾼다면 감정사도 이게 잘못만든 진품인지 잘만든 가품인지 구분하기 힘들기 때문입니다.
그렇기에 G는 천천히 변화해야 합니다.
그래프를 한번 보실까요

이건 분포 그래프로 표현한 G, D라고 보시면 됩니다
파랑선: D의 분포 (판별 분포)
초록선: G의 분포 (생성 분포)
검정선: 데이터 분포 (학습 샘플 데이터의 분포)
a, b, c를 반복하다 d가 되는것으로 위 그래프를 보시면 D를 최적화 -> D를 바탕으로 G를 최적하는것을 확인 가능합니다.

다음은 이론적 결과를 알아볼 시간입니다.
재명씨가 잘 설명해줄 수 있을거라 생각합니다.

동훈씨 매우 칭찬합니다~ 이제 좀 정신을 차린 것 같습니다. 그럼 제가 설명한번 해보겠습니다.

상인이 가짜 지갑을 100번 만들면 98번째부터는 진품과 구분이 힘들어지는 것! 이게 바로 p값 수렴이라는 겁니다. 그것을 알고리즘으로 나타낸것이 아래에서 설명할 알고리즘1입니다.
또한 상인의 위조기술이 명품공장 수준에 도달했을 때(G와 data의 분포 일치) 가 최저점임을 증명해야합니다. 사람들과 다르게 모델은 최저점을 찾아 학습을 진행하기 때문이지요.

죄송하지만 진품을 위조하는것 그것이 불법이라는 사실은 알고서 말씀하시는 겁니까?
해석하기에 따라 그 발언은 위조를 권장하는 발언으로도 보일 수 있습니다.

하하.. 상인은 대한민국 국민이 아닙니까? 명품이라는 이유로 대기업을 감싸면 소상공인은, 국민은 누가 보호해줍니까? 명품을 위조한 짝퉁으로 인해 명품이 무너진다면 그 또한 시장경제 체제를 따른다고 볼 수 있겠지요. 열심히 사는 상인은 저희가 보호해야합니다! 소상공인이야 말로 대한민국의 미래이니까요.

(하.... 또 지랄을 하네) 설명이나 마저 하시죠


이어서 알고리즘1에 대해서 알아봅시다.
수학식이 위, 아래 하나씩 있는거 보이시죠?
위 식은 감정사를 최적화 시킬때 사용하는 확률적 경사하강법이고 아래식은 상인을 최적화 시키는 식입니다.
감정사 최적화는 세무조사관이 자영업자 단속하는 것과 똑같습니다! 명품(진품) m개, 상인제작품(가짜) m개를 골라서 랜덤 샘플링으로 조사합니다. 이게 바로 저 윗줄 수식의 의미지요
상인 최적화는 상인이 감정사 눈치만 보는것과 같습니다. 자기네 공장에서 만든 물건 m개만 들고 노이즈 추출 기술로 감정사를 테스트하는 거죠. 진품 데이터는 쳐다보지도 않아요!
즉 위 알고리즘은 GAN의 경사하강법에 대한 설명이라고 볼 수 있습니다.
다음 부분부터는 수학지식이 많이 필요하니 명문대 출신 동훈씨가 설명해주실겁니다.

감사합니다. 저와 같이 4.1을 같이 보시죠

여기에서는 G의 분포와 data의 분포의 전역 최적성에 대해 알아봅니다.
여기서 전역 최적성은 G와 data의 분포가 같을 때 최적의 상태라는것을 말하는 것이지요.
명제는 G가 고정인 상황에서 D는 2번식과 같다는 것입니다. 즉, 고정된 G 하에서 판별기(D)의 행동은 형사소송법 제312조(증거능력 판단 기준)를 적용한 것과 동일합니다. D는 다음 두 가지를 엄격히 입증해야 합니다:
진품 데이터에서의 log(D(x)) 값 극대화, 생성품에서의 log(1−D(G(z))) 값 극대화. 이 과정은 검찰의 2단계 증거심사와 본질적으로 동일합니다.
후에 3번식을 보시면 V(G,D)는 [0,1]에서 a/(a+b)일 때 최대값을 가지게 된다는 것을 알 수 있습니다.
4번식의 C(G)는 G의 최적값을 알려주는 함수이자 손실함수 입니다. 해당 식의 전개과정은 조금 이따가 한번에 풀도록 하겠습니다.



이어서 설명하겠습니다.

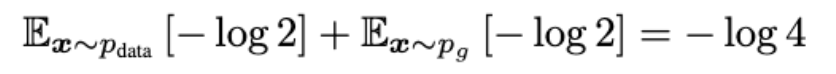
이 식을 아까 설명했던 C(G)에서 빼고 난 뒤 쿨백-라이블러 발산을 적용하면 5번과 같은 식이 나옵니다.
그 5번식에 JSD로 변환을 거치면 6번식이 나오고 6번식을 통해 data와 G의 분포가 같을때만 전역 최솟값이라는 것을 알 수 있습니다.

자세한 설명 부탁드리겠습니다.

안그래도 어려울 수 있을 것 같아 준비해왔습니다.

여기까지는 이해가 되실거라 믿습니다.
그럼 이제 C(G)에서 뺄셈 부터 수행해보겠습니다.

그럼 위에서 말했던 대로 쿨백 라이블러 발산을 적용해볼까요?

이제 JSD에 대해 알아보고 변환을 진행할 시간입니다.


어떻습니까? 오뎅먹기처럼 쉽지 않습니까?

오뎅이라니 친일파이십니까? 어묵이라는 단어를 사용하셔야죠

일본어가 어원인 단어를 사용하면 다 친일파다 이런 말씀이십니까?
근데 어묵이라는 단어의 어원도 일본이라는 것을 아십니까?

X치고 설명이나 할것이지 어린게 싸가지가없어

빨리 이어서 설명하겠습니다.
4.2 챕터입니다.
2번째 명제부터 알아보죠
G에 대한 최적의 D이며 G는 위 식을 개선하며 업데이트하면 G의 분포는 data의 분포로 수렴한다. 라는 내용입니다.
다시 설명드리자면 위 식을 따르도록 모델을 훈련시키면 G의 분포가 data의 분포로 수렴한다는거지요 4.1에서 p_g = p_data일때 최소라는것을 알았으니 이번에는 p_g가 p_data로 수렴하는지에 대해 알아보는 시간이 되겠습니다.


위 논문을 보면 볼록 함수의 상한의 부분 미분은 최대값이 달성되는 지점에서의 함수의 미분을 포함한다 라는 말이 적혀있습니다. 이 말이 무슨뜻인지 친절히 설명드리도록 하겠습니다.

이제 위 내용들을 바탕으로 증명을 시작해보도록 하겠습니다.

다시 논문을 보시면 아래와 같은 내용이 적혀있습니다.

이 문장을 해석해보겠습니다.


이렇게 증명이 되는겁니다. 생각보다는 어렵지 않지요?
종합결과에 대해서는 재명씨가 해주시겠습니까?

물론입니다.

GAN은 G의 분포라는 이상적 분포를 쫓는 대신, 실제 조정 가능한 G의 매개변수에 집중합니다. 또 다층 퍼셉트론을 사용하면 critical point라는 문제들이 생기긴 합니다.

critical point (미분이 안되거나 0인 점)들이 있음에도 계속 사용하는 이유가 무엇입니까?

critical point? 그건 장관들이 서류에 도장 찍다 막히는 관료적 장애물과 똑같습니다! 이론적 완벽함보다 현실 적용 속도가 중요하다 이 말입니다! 이론적 보장이 없어도 현장에서 통하면 장땡! 국민 눈높이에 맞는 정책이 진짜 혁신이듯이 말입니다!

재명씨는 맞는말을 거짓과 섞는 재주가 있으시군요...
글이 꽤나 길어졌으니 다음 부분은 다음 포스팅과 함께하도록 하겠습니다.

즐겁게 봐주셨나요?
다시한번 말씀드리지만 이 포스팅의 등장인물은 전부 가상인물이며 실존인물과 아무런 관련이 없습니다!
지적은 언제나 환영합니다. 좋은하루되세요!
'이 멋진 논문에 축복을!' 카테고리의 다른 글
| 리재명과 환동훈의 논문 핥아보기 - Generative Adversal Nets - 2 (0) | 2025.02.26 |
|---|